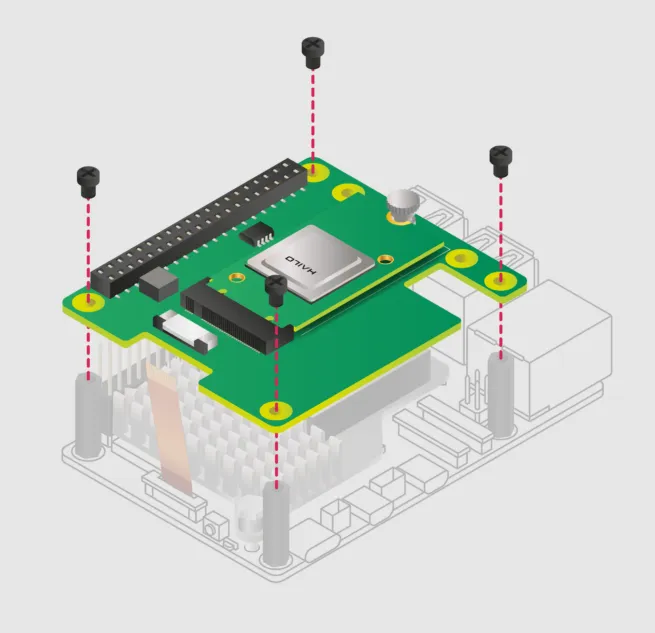
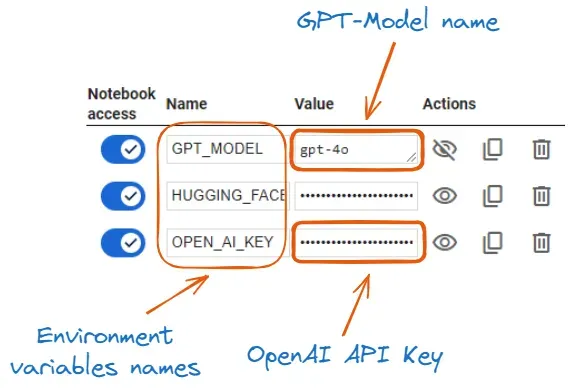
本指南将引导您在 Raspberry Pi 5 上成功安装 Raspberry Pi AI Kit,使您能够利用 Hailo AI 神经网络加速器运行 rpicam-apps 摄像头演示。 如果您在安装人工智能套件之前需要协助,本指南提供了详细的分步图片说明。有关人工智能套件的安装过程,请参考以下链
 发布于 2024-09-17
发布于 2024-09-17
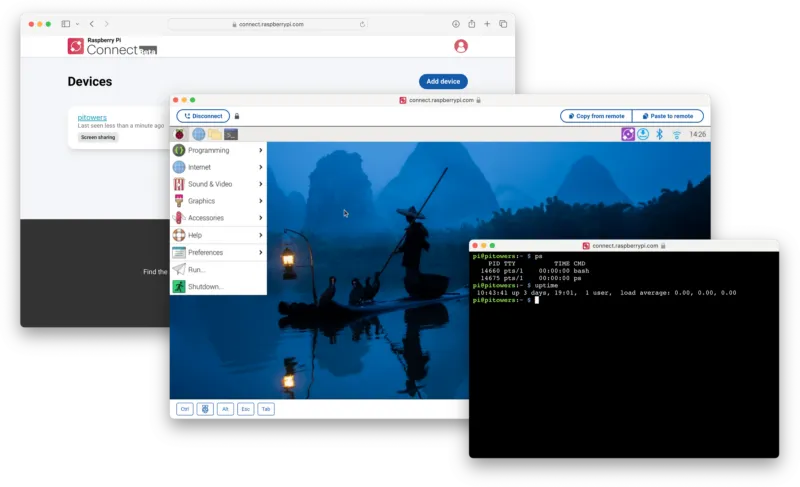
一个半月前,我们推出了 Raspberry Pi Connect,旨在让您能够在全球范围内轻松远程访问 Raspberry Pi 设备。我们一直在认真倾听您的反馈,了解您对这项服务的期待。今天,我们欣然宣布最新的测试版发布,将 Raspberry Pi Connect 扩展到更多的设备上。Raspb
发布于 2024-09-17
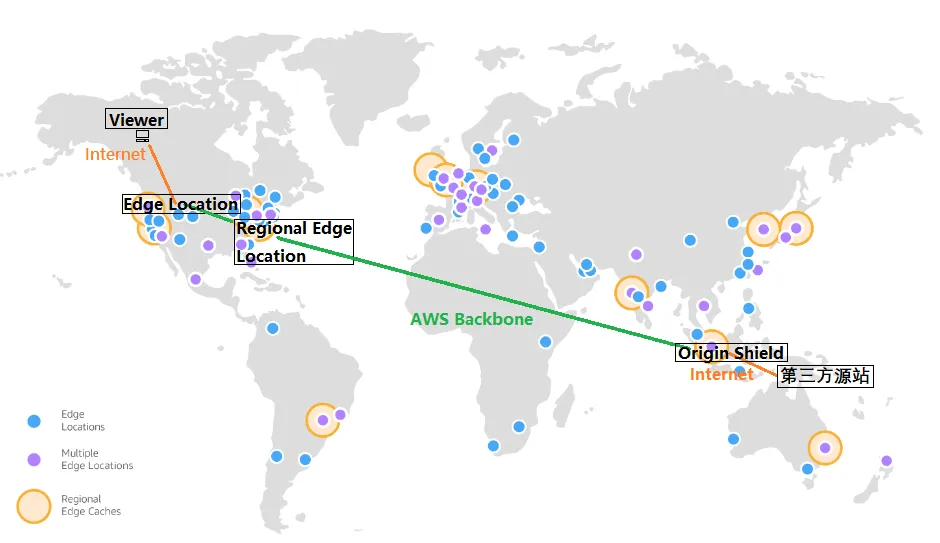
前言 网络连接与基础设施 CloudFront的边缘站点通过AWS的主干网络与各个区域相连接。该骨干网络是一个完全冗余的全球性基础设施,由多个100GbE的平行光纤组成,并与数以万计的网络连接相结合,以提升源内容获取的效率和动态内容的加速能力。 为了以更低的延迟将内容分发给最终用户,Amazon C
发布于 2024-09-17
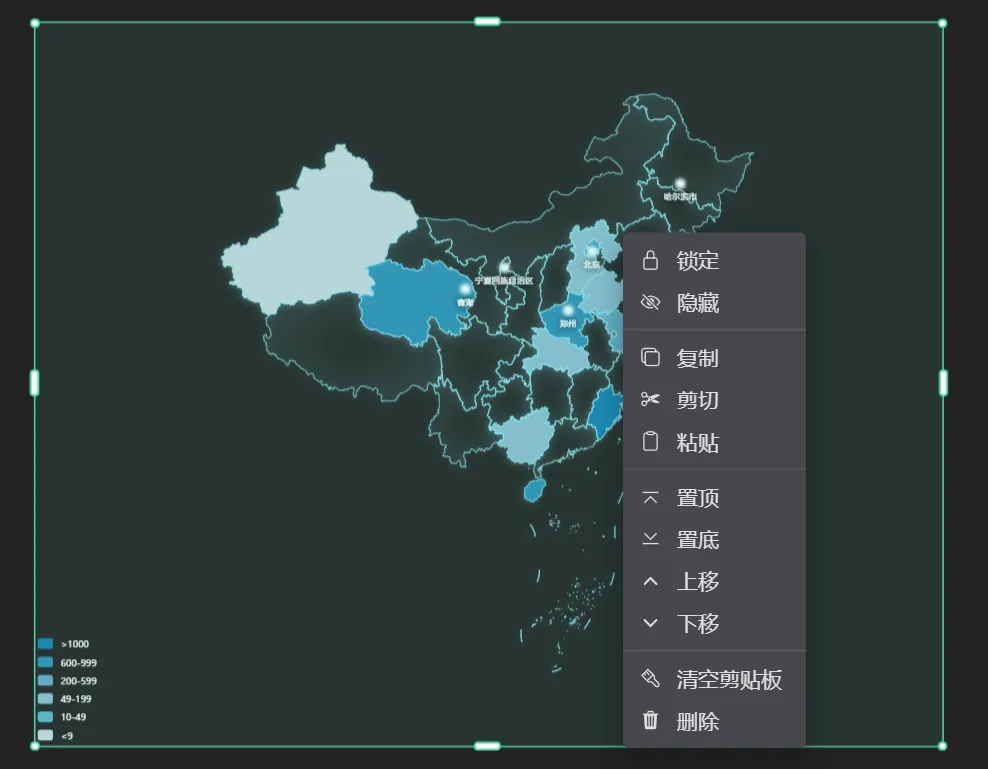
GoView 是一款功能强大、性能卓越的低代码数据可视化开发设计器,基于 Vue3 构建。它将图表、边框、装饰和文本等元素封装为基础组件,提供丰富的组件库和灵活的配置选项,结合优雅的交互设计,帮助用户快速构建和定制数据驱动的应用程序,无需编写额外代码即可满足业务逻辑的需求。 技术栈 Vue3 + T
发布于 2024-09-15
AI Agent 是一种通过编程能够执行特定任务、做出决策并协作实现共同目标的智能体。每个智能体都有其独特的技能和角色,利用大型语言模型(LLMs)作为推理引擎,支持高级决策和高效完成任务。它们的自主性和适应性在多智能体系统中的动态交互和流程管理中至关重要。 这些智能体还能够调用外部工具以扩展其能力
发布于 2024-09-15
ollama与Obsidian的结合可以有效读取Obsidian中的所有文档,实现本地知识库的问答以及与大型模型的对话。这种方式相较于我之前介绍的ollama+MaxKB,构建本地AI知识库而言,无需进行额外的部署和上传文档到其他平台。这种组合对于像我这样使用Obsidian作为写作工具的文字工作者
发布于 2024-09-15
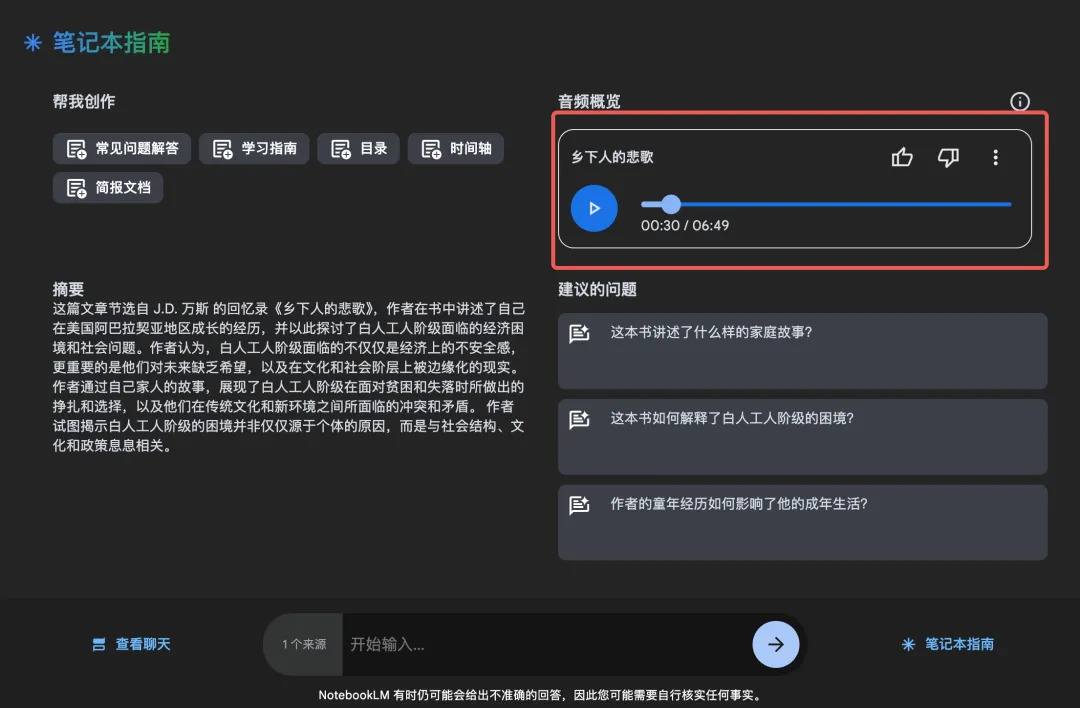
引入革命性的播客生成功能 谷歌推出了其AI笔记应用NotebookLM的一个令人惊艳的新功能:它能够理解用户上传的文档、链接以及文本信息,并生成互动式播客。在播客中,两位主播进行生动的对话,让人很难分辨出这是由AI生成的内容。无论是音质还是内容的丰富性,这项功能都表现得相当出色。 在体验了这一新功能
发布于 2024-09-15
 发布于 2024-09-15
发布于 2024-09-15
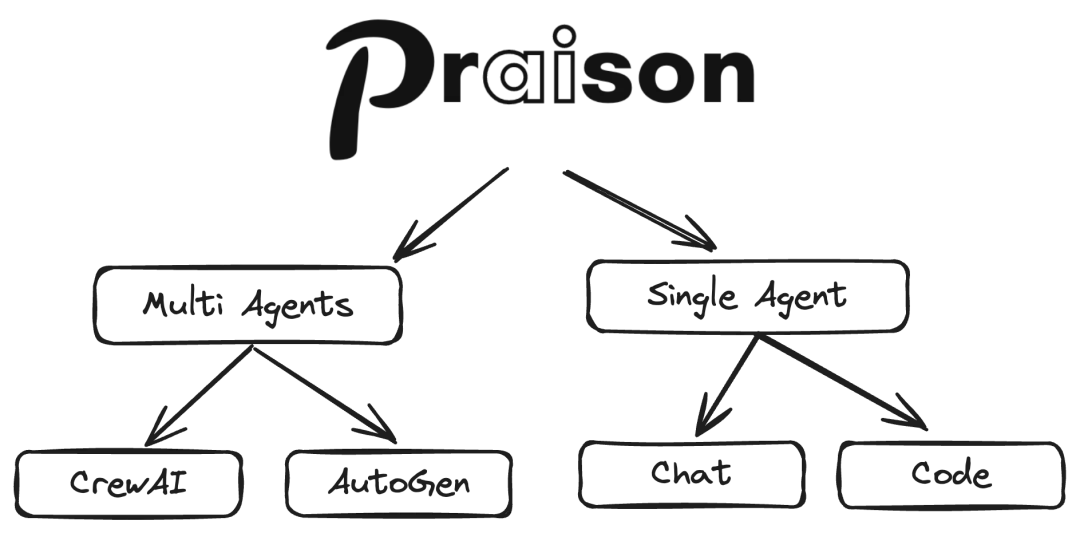
这是一个结合了AutoGen 和 CrewAI的开源项目,旨在构建和管理多代理大型语言模型(LLM)系统。 由于AutoGen和CrewAI(详细介绍见文末)已经实现了封装,因此基于CrewAI的开源项目也曾得到广泛关注。 CrewAI本身基于Langchain进行了一系列开发,因此Praison
发布于 2024-09-15
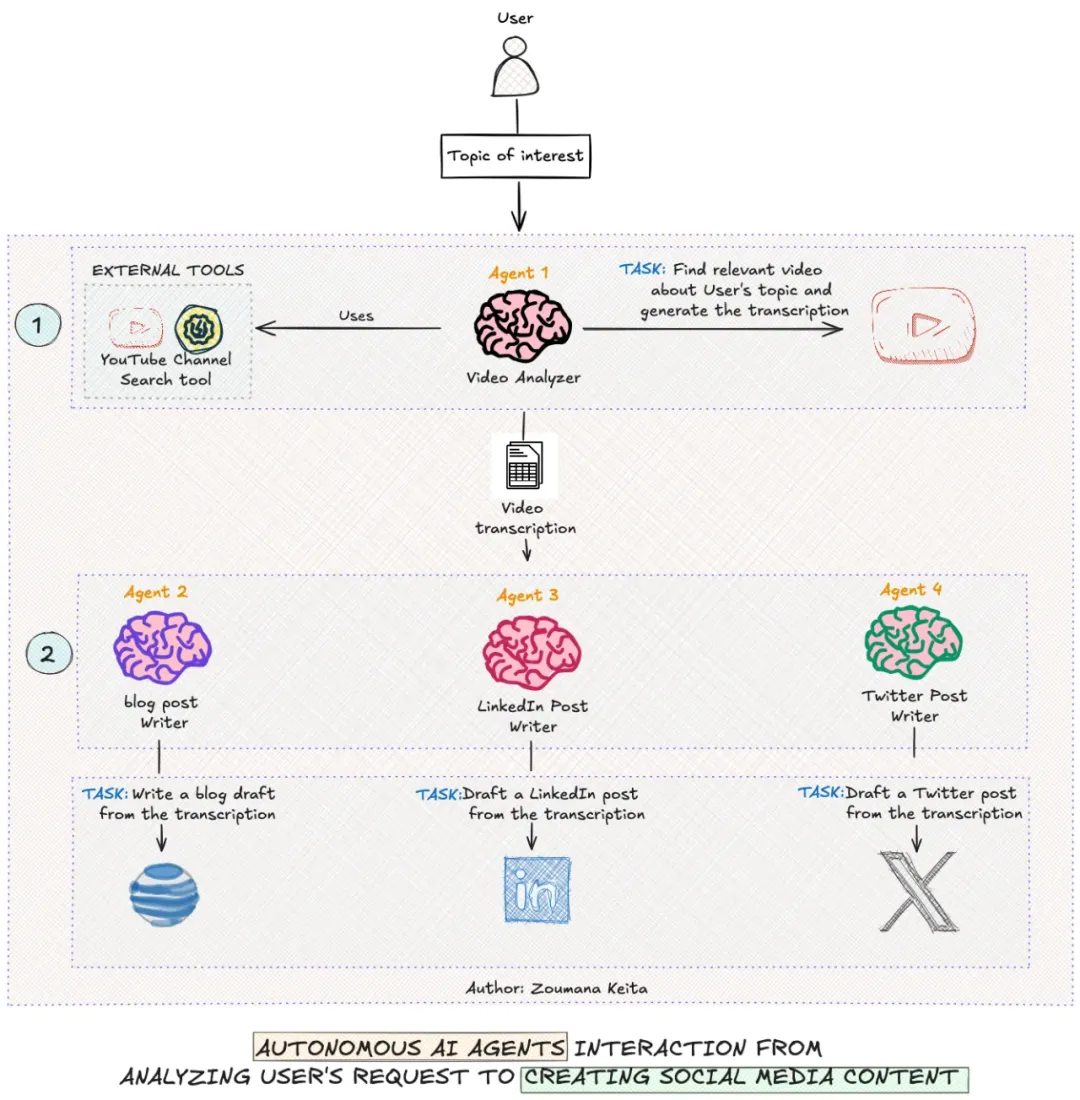
有句非洲谚语非常著名:“一个人可以走得很快,而一群人才能走得更远。”这句话传达了团队合作的重要性,强调了分工明确和协同合作的力量。正如这句话所示,只有在团队成员各尽其职、共同努力时,才能真正取得成功。 这个理念同样适用于大型语言模型(LLM)。我们不必期望一个单一的 LLM 能够处理所有复杂的任务。
发布于 2024-09-15

深入分析中国芯片行业的现状 苹果已开始逐渐抛弃英伟达。 18个月前,ChatGPT的推出引发了人工智能的热潮,英伟达成为这一浪潮的领头羊。其市值超过苹果,成为全球最大的市值公司,股价上涨了600%。首席执行官黄仁勋因此被称为“科技界的泰勒·斯威夫特”,众多硅谷巨头纷纷希望能与其见面。 然而,历史的恩
发布于 2024-09-15

**“在互联网泡沫之前,我们也相信思科会一直涨下去。”**这句话曾是华尔街投资人对思科的评价。或许由于思科带来的创伤过于深刻,英伟达在2025财年第二季度公布财务数据后,尽管各项业务都在提升,投资者却纷纷选择撤离。 原因在于,英伟达的增速显著放缓。 **本季度英伟达实现营收300.4亿美元,同比增长
发布于 2024-09-15

最近,PyTorch官方发布了关于无CUDA计算的实现方法,并对各个内核进行了微基准测试比较,探讨了未来如何进一步优化Triton内核,以缩小与CUDA的性能差距。 在训练、微调和推理大语言模型(LLM)时,使用英伟达的GPU和CUDA已经成为一种普遍做法。同样,在更广泛的机器学习领域,CUDA的依
发布于 2024-09-15
开源AI工作流项目,这些项目的GitHub星标数量均超过一万。它们的共同特点包括:1. 提供友好的图形化界面,支持拖拉拽操作,适合没有编程基础的业务人员;2. 支持自定义知识库、工作流、自定义插件和大型模型;3. 提供多种预设的应用模板和API工具。其中,前三个项目均由国内公司开发,Dify和Flo
发布于 2024-09-15

在当今数据驱动的时代,计算能力已成为科技进步的重要推动力。GPU曾经专注于图形渲染,但如今已成为高性能计算的核心力量。这一转变离不开英伟达革命性的技术——CUDA。 什么是CUDA? CUDA,全称为Compute Unified Device Architecture,即统一计算设备架构,是英伟达
发布于 2024-09-15

什么是CUDA CUDA(Compute Unified Device Architecture)是英伟达推出的基于其GPU的通用高性能计算平台和编程模型。通过CUDA,开发者能够有效利用英伟达GPU的强大计算能力,以加速各种计算任务。 软件生态的基石 CUDA构成了英伟达软件生态的基础,许多前沿技
发布于 2024-09-15

Introduction Understanding the Basics of CUDA GPU programming involves multiple components such as the CPU, GPU, memory, and video memory. It's crucia
发布于 2024-09-15
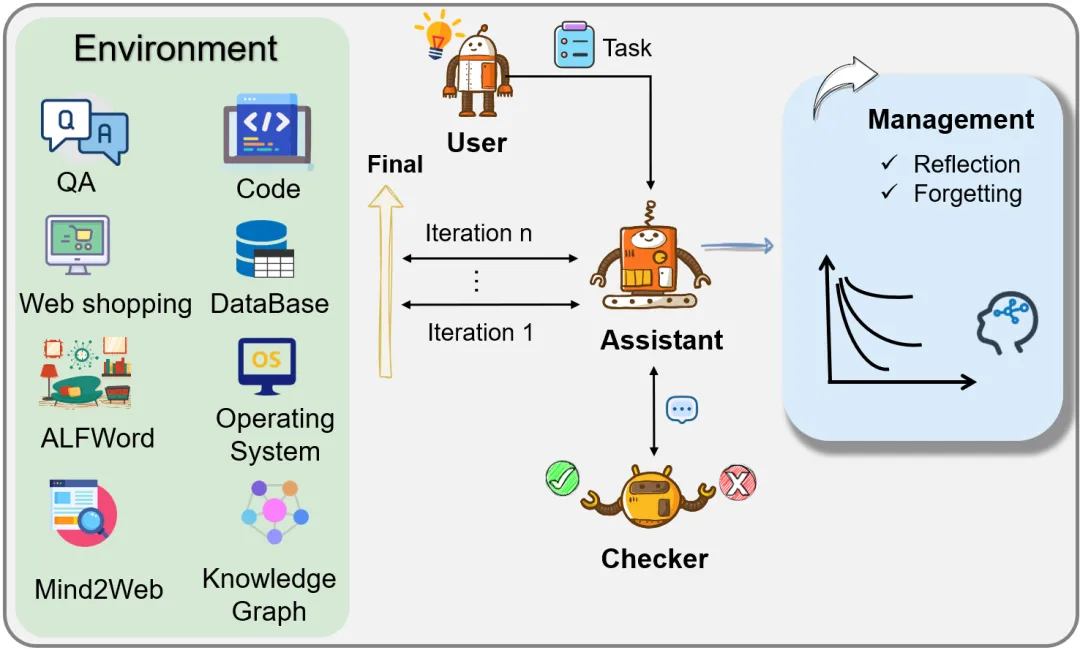
在动态环境中,大型语言模型(LLMs)在持续决策、长期记忆和有限上下文窗口等方面仍存在诸多挑战: 通过元学习和多任务学习等方法,增强LLMs的迁移能力和适应性; 针对有限记忆存储的问题,MemGPT和MemoryBank采用了不同的策略进行记忆管理; 然而,这些方法通常专注于特定任务或场景,缺乏通用
发布于 2024-09-15