
最近,PyTorch官方发布了关于无CUDA计算的实现方法,并对各个内核进行了微基准测试比较,探讨了未来如何进一步优化Triton内核,以缩小与CUDA的性能差距。 在训练、微调和推理大语言模型(LLM)时,使用英伟达的GPU和CUDA已经成为一种普遍做法。同样,在更广泛的机器学习领域,CUDA的依
 发布于 2024-09-15
发布于 2024-09-15
开源AI工作流项目,这些项目的GitHub星标数量均超过一万。它们的共同特点包括:1. 提供友好的图形化界面,支持拖拉拽操作,适合没有编程基础的业务人员;2. 支持自定义知识库、工作流、自定义插件和大型模型;3. 提供多种预设的应用模板和API工具。其中,前三个项目均由国内公司开发,Dify和Flo
发布于 2024-09-15

在当今数据驱动的时代,计算能力已成为科技进步的重要推动力。GPU曾经专注于图形渲染,但如今已成为高性能计算的核心力量。这一转变离不开英伟达革命性的技术——CUDA。 什么是CUDA? CUDA,全称为Compute Unified Device Architecture,即统一计算设备架构,是英伟达
发布于 2024-09-15

什么是CUDA CUDA(Compute Unified Device Architecture)是英伟达推出的基于其GPU的通用高性能计算平台和编程模型。通过CUDA,开发者能够有效利用英伟达GPU的强大计算能力,以加速各种计算任务。 软件生态的基石 CUDA构成了英伟达软件生态的基础,许多前沿技
发布于 2024-09-15

Introduction Understanding the Basics of CUDA GPU programming involves multiple components such as the CPU, GPU, memory, and video memory. It's crucia
发布于 2024-09-15
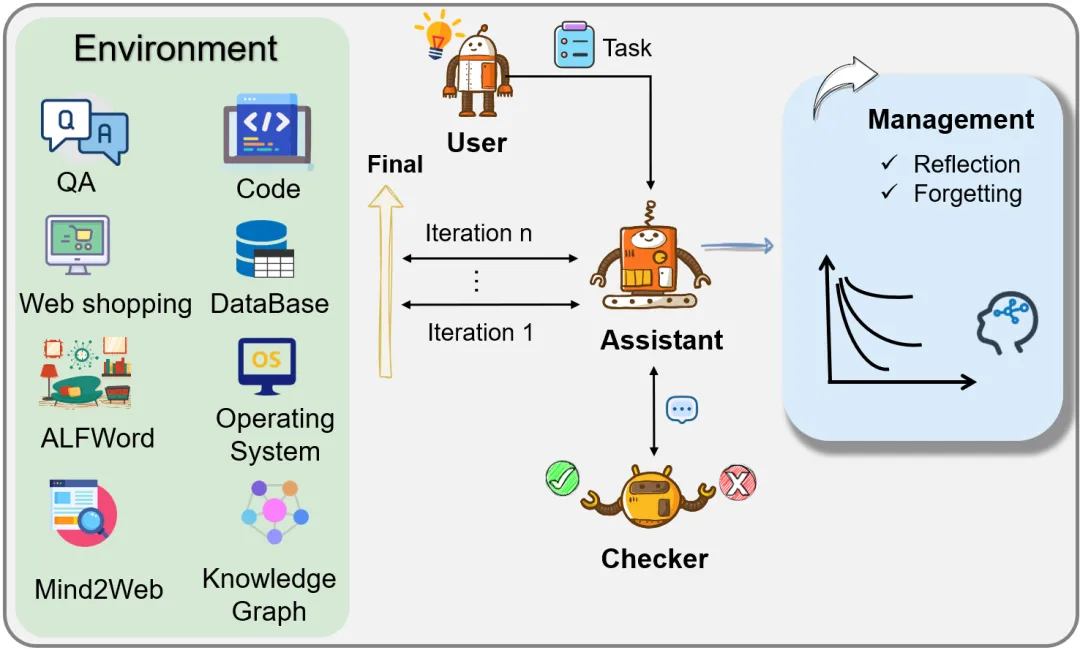
在动态环境中,大型语言模型(LLMs)在持续决策、长期记忆和有限上下文窗口等方面仍存在诸多挑战: 通过元学习和多任务学习等方法,增强LLMs的迁移能力和适应性; 针对有限记忆存储的问题,MemGPT和MemoryBank采用了不同的策略进行记忆管理; 然而,这些方法通常专注于特定任务或场景,缺乏通用
发布于 2024-09-15
环境介绍 在本指南中,我们将使用三台设备进行FRP内网穿透的搭建,包括:本地攻击机、远程跳板机和远程目标服务器。首先,请根据目标服务器的操作系统环境下载相应版本的FRP(推荐为0.46.0版本)。 请确保下载安装Proxifier,并使用工具 python Proxifier_Keygen.py -
发布于 2024-09-15
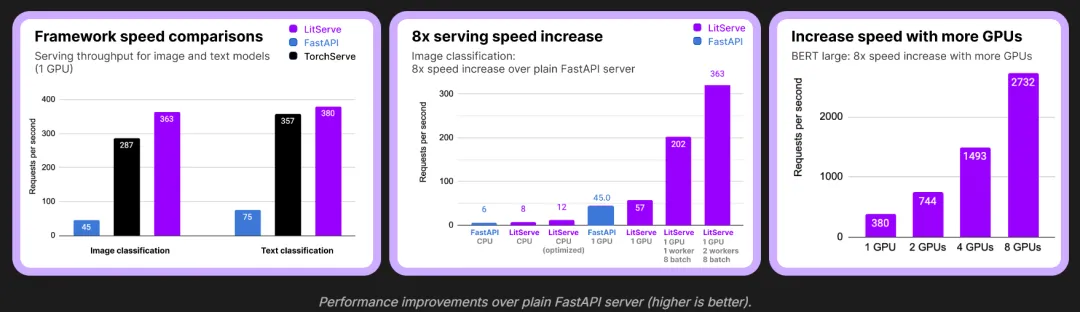
欢迎阅读本期文章! LitServe是一款灵活且易于使用的服务引擎,专为基于FastAPI构建的AI模型而设计。其具备批处理、流式处理和GPU自动扩缩等功能,无需为每个模型重复搭建FastAPI服务器。 LitServe的优势特性
发布于 2024-09-15
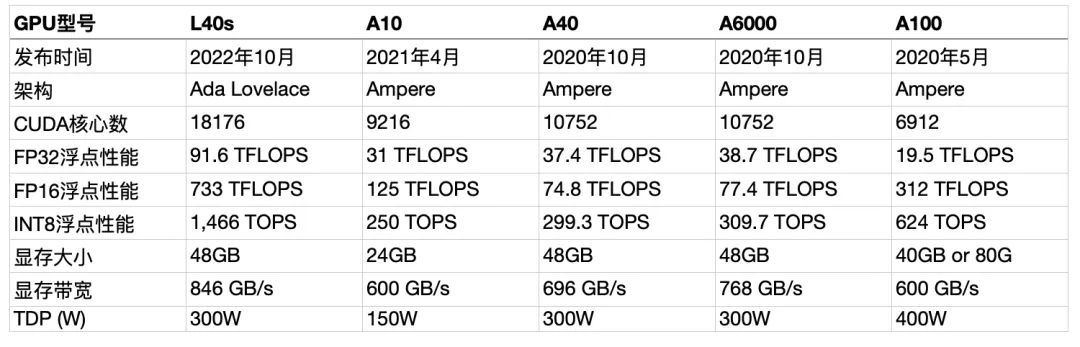
近年来,随着人工智能技术的不断演进,尤其是深度学习模型的广泛应用,GPU(图形处理单元)作为加速计算的重要硬件在AI领域发挥着越来越重要的作用。AI推理即已训练好的模型对新数据进行预测的过程,其对GPU的需求与训练阶段有所不同,更加关注能效比、延迟及并发处理能力。本文将基于这些因素,对NVIDIA的
发布于 2024-09-15
概述 AutoGen是一个开源编程框架,旨在构建AI Agent并促进多个Agent之间的协作,以解决各种任务。该框架的目标是为人工智能开发和研究提供一个灵活且易于使用的环境,类似于深度学习领域的PyTorch。AutoGen具备多个功能,包括可交互的Agent、LLM和工具的支持、自主与人机循环工
发布于 2024-09-15