
本文将详细解析如何在树莓派上运行大型语言模型(LLM),探讨其是否可作为ChatGPT和GitHub Copilot等工具的实用替代方案。您可通过下方视频深入了解树莓派运行LLM的实际效果(作为编程助手),并对比树莓派5与内置NPU的单板计算机(如Radxa Rock 5C)的性能差异。
本地运行LLM带来多重优势:
您无需依赖价值数十亿美元的公司,这些公司可能随时修改服务条款。
所有数据均保存在您的计算机或本地网络中,确保最高级别的隐私保护。
可自由尝试不同LLM模型,这些模型无法通过ChatGPT等付费订阅服务获得。
如何在树莓派上安装和配置Ollama运行大型语言模型
Ollama简化了在树莓派上本地安装和运行LLM的过程。您只需连接互联网下载模型,后续所有操作均在本地完成。使用以下命令快速安装:
curl -fsSL https://ollama.com/install.sh | sh若需从其他设备连接Ollama,需设置环境变量以启用服务。第一个变量将服务绑定到树莓派的所有IP地址,第二个变量取决于访问方式(IP或主机名)。确保替换<IP或主机名>为您的实际值。本文以IP地址为例。
编辑文件 /etc/systemd/system/ollama.service,添加以下内容:
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=http://<IP or Hostname>:11434"重启Ollama以应用更改:
sudo systemctl daemon-reload
sudo systemctl restart ollama在浏览器中访问 http://<IP地址>:11434,若显示"Ollama正在运行"即表示成功。若出现连接错误,请复查环境变量配置。
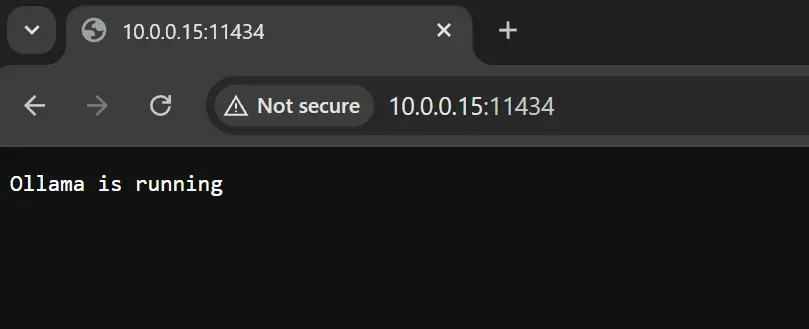
Open WebUI(后续详述)支持从Web界面下载模型,但建议使用终端操作。所有Ollama官网列出的模型均可下载到树莓派(访问 https://ollama.com/search)。
建议从1.5B参数模型开始,其在树莓派有限资源下平衡了准确性和计算效率。
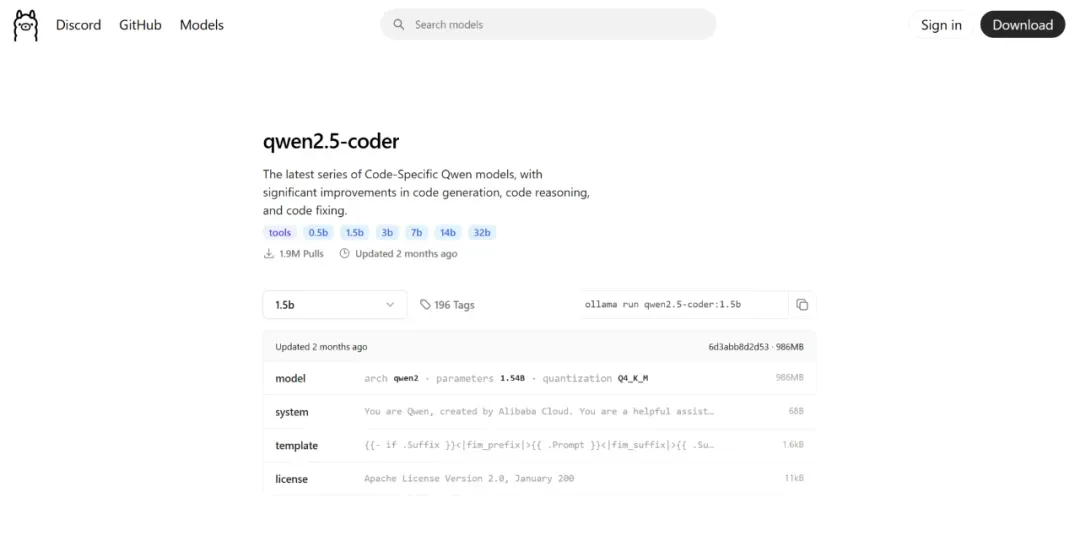
复制Ollama官网的run命令到终端执行:
ollama run qwen2.5-coder:1.5b设置Open WebUI实现用户友好聊天交互
启动Ollama后,虽可直接在终端聊天,但体验较笨拙。Open WebUI提供类似ChatGPT的现代化交互界面,以Python包形式安装。从树莓派OS Bookworm起,需创建虚拟环境:
python -m venv myenv此命令创建名为myenv的文件夹,包含Python环境文件。激活环境:
source myenv/bin/activate使用pip安装Open WebUI包:
pip install open-webui安装完成后启动服务器:
open-webui serve服务器默认端口为8080。在浏览器中输入树莓派IP地址:8080访问LLM聊天机器人。登录界面将出现,创建本地账户(信息不通过互联网传输)。
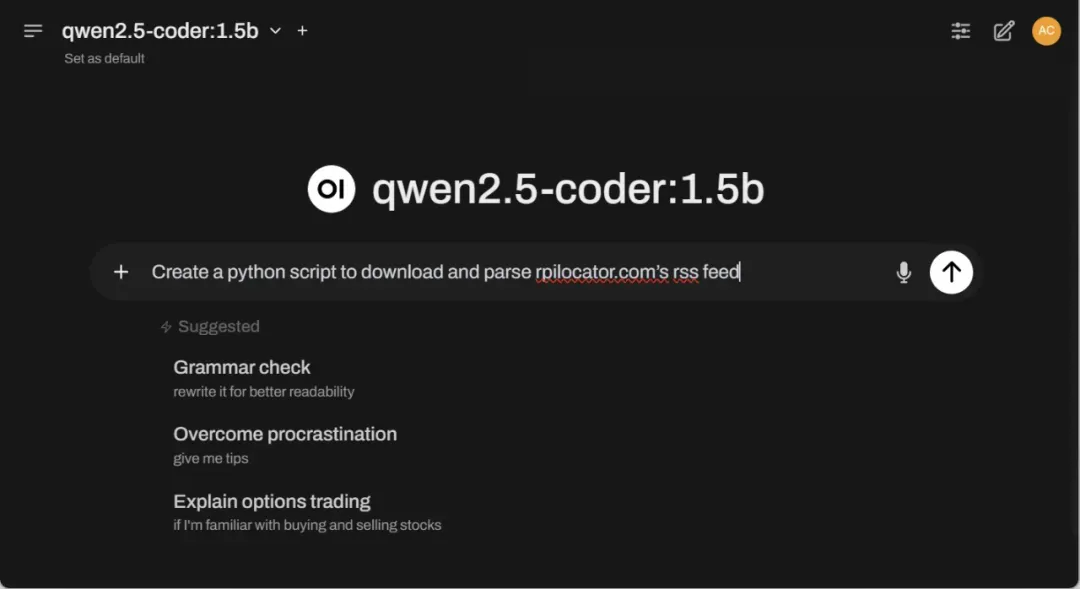
登录后,使用聊天框协助编码任务。
如何集成VS Code插件Continue实现代码自动完成
若需将Ollama直接集成到VS Code等编辑器(提供类似Copilot的自动完成功能),需额外配置。默认设置可能发送过多上下文数据,导致树莓派5超时。
打开Continue设置,在config.json中添加以下代码块限制提示令牌:
"tabAutocompleteOptions": {
"maxPromptTokens": 300
}确保自动完成设置匹配模型和树莓派IP地址。以下示例使用Qwen2.5编码器模型:
"tabAutocompleteModel": {
"title": "Qwen2.5-Coder",
"provider": "ollama",
"model": "qwen2.5-coder:1.5b",
"apiBase": "http://10.0.0.41:11434"
}